 INGInious
INGIniousWe are now going to study another graph exploration algorithm called depth-first search (DFS). As we will see, DFS is extremely useful and we can solve a wide number of graph related problems with this algorithm.
In DFS we start from a source node and then recursively visit each of its neighbours. Because of this recursive behavior, after we select the first neighbour \(u\) of \(v\) to be explored, the other neighbours of \(v\) will only be considered after we have finished visiting the whole subgraph that is reachable from \(u\). This is the reason why this algorithm is called depth-first search. To better illustrate this, consider the following example.
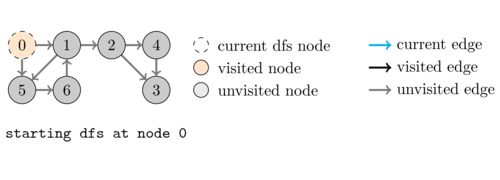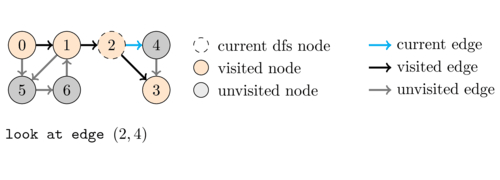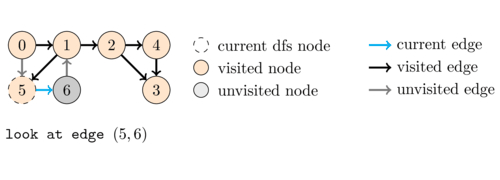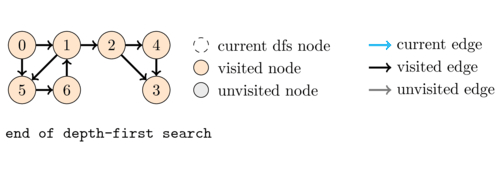
Coding this algorithm is very simple as shown in the following code:
static LinkedList<Integer>[] g;
static boolean[] visited;
static void dfs(int u) {
visited[u] = true;
for(int v : g[u]) if(!visited[v]) dfs(v);
}
If we execute the following code:
... boolean[] visited = new boolean[g.length]; dfs(0);
Then visited will be set to \(true\) for every node that is reachable from node \(0\). In this way, DFS is a much more compact way of coding an algorithm to check for path existence.
So far this does not really gives us something new. There are several ways in which we can extend this algorithm in order to solve different problems.
Before we do so, it is often convenient to have a more informative state of each node during the search rather than a simple flag saying whether a node as been visited or not. We will start by replacing the visited array by an array of integers called state and define 3 possible states:
static final int UNV = 0, OPEN = 1, CLOSED = 2;
These 3 states have the following semantics:
- \(state[u] = \textit{UNV}\) : node \(u\) has not been visited before. This corresponds to \(visited[u] = false\) from before.
- \(state[u] = \textit{OPEN}\) : node \(u\) has been visited but not all of its outgoing edges have been visited.
- \(state[u] = \textit{CLOSED}\) : means that all the edges going out of \(u\) have been visited.
To extend the previous code to use the array state respecting these semantics is quite simple. Every node should start with the state \(\textit{UNV}\). Then the first line should set the state to \(\textit{OPEN}\) since at this point the node is visited but we did not yet visit any of its outgoing edges. Finally, after the for loop finished we should set the state to \(\textit{CLOSED}\). We will also add an array \(parent\) to keep for each node, who visited it as we did in the BFS algorithm.
static final int UNV = 0, OPEN = 1, CLOSED = 2;
static LinkedList<Integer>[] g;
static int[] state;
static Integer[] parent;
static void dfsVisit(int u) {
state[u] = OPEN;
for(int v : g[u]) {
if(state[v] == UNV) {
parent[v] = u;
dfsVisit(v);
}
}
state[u] = CLOSED;
}
Note: In Java when you create the \(state\) array every value is initialized to \(0 = UNV\). Therefore nothing needs to be done. In some other languages you need to make sure that you set the value of every node \(UNV\) before you start the search.
The following animation illustrates an execution of \dfsVisit(0).
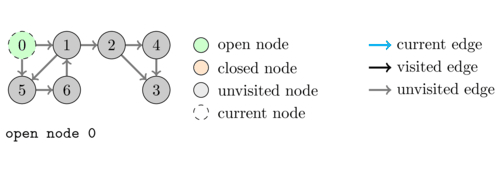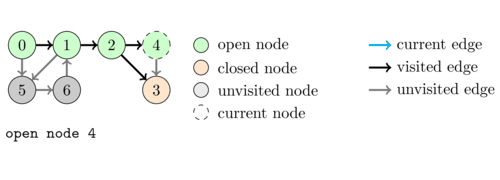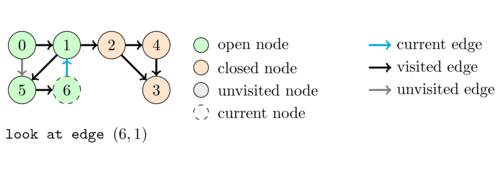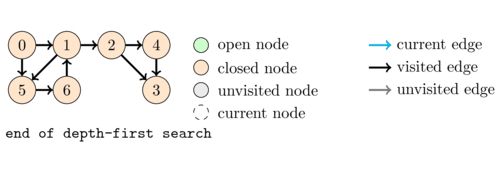
As a first application of DFS we are going to see how we can use the states to simply check whether a directed graph contains a cycle.
Note that the parent array defines a tree that is a subgraph of the input graph. We call it the DFS tree. To detect a cycle we make the following observation:
- During the execution of
dfsVisit(u), if any node \(v\) is \(OPEN\) then there exists a path from \(v\) to \(u\) on the DFS tree. This is so because since \(v\) is still open and we are at node \(u\) then \(v\) must be an ancestor of \(u\) in the DFS tree.
Therefore if during the for loop at node \(u\) we find a neighbour \(v\) that is \(OPEN\) we must have a cycle in the graph since, as we just observed, this means that there is a path from \(v\) to \(u\) and this path together with the edge \((u, v)\) must form a cycle.
We classify the edges of the graph in 4 categories with respect to a DFS.
- Tree edges: edges that belong to the DFS tree.
- Cycle edges (or back edges): edges from a descendant node to one of its ancestors. They occur when at some point we have an edge between two \(OPEN\) nodes.
- Forward edges: a non tree edge from an ancestor node to a descendant node.
- Cross edges: edges between two nodes such that neither is an ancestor of the other.
The following animation illustrates the execution of DFS together with the DFS tree and the different kinds of edges.
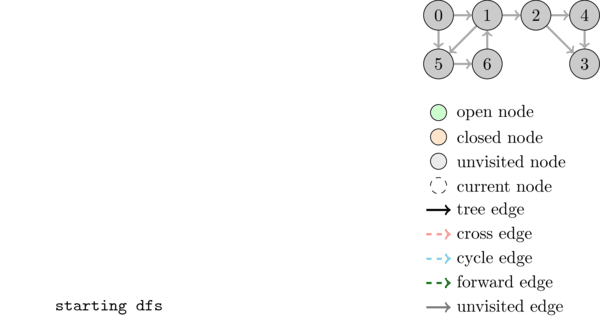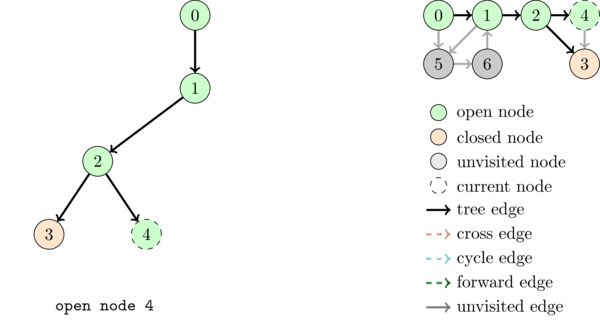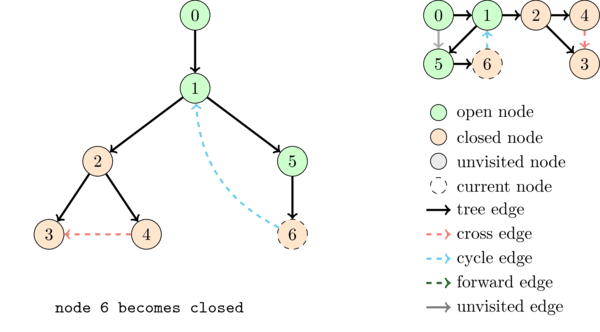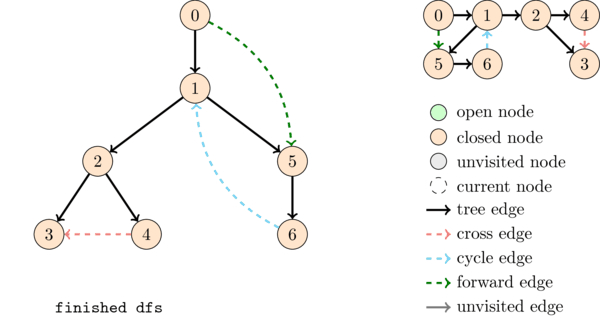
We saw above that if there is a cycle edge in a graph then the graph contains a cycle. It is not hard to see that the converse is also true, that is, if there is a cycle then there is a cycle edge. Thus we can detect cycles as follows:
static final int UNV = 0, OPEN = 1, CLOSED = 2;
static LinkedList<Integer>[] g;
static int[] state;
static Integer[] parent;
static boolean foundCycle;
static void hasCycle() {
foundCycle = false;
state = new int[g.length];
parent = new Integer[g.length];
for(int u = 0; u < g.length; u++) {
if(state[u] == UNV) {
dfsVisit(u);
}
}
}
static void dfsVisit(int u) {
state[u] = OPEN;
for(int v : g[u]) {
if(state[v] == UNV) {
parent[v] = u;
dfsVisit(v);
} else if(state[v] == OPEN) {
// (u, v) is a cycle edge, the graph contains a cycle
foundCycle = true;
}
}
state[u] = CLOSED;
}
The graph has a cycle if and only if after executing hasCycle() we have foundCycle == true.
The complexity of performing a DFS is \(O(V + E)\) as the total work we perfom per node \(v\) is \(O(outdeg(v))\) and